初识 React, Flux 和 Redux
Updated:
近期,我大概花了一周,每天晚上 2 小时左右和一个周末的时间,通过官方文档来了解 React, Redux, Flux 几个框架和概念。写下此文是希望帮自己梳理和巩固一下对它们的认识。如果哪里理解有误,希望大家不吝指出。
React
围绕 JavaScript 来设计的思想,把所有的 Component,都化作 JavaScript 的一个 function 或者 object,通过丰富的工具来支持类型,错误检查等确实是很赞的想法。如果使用的是 AngularJS 这样的模板和自定义 directive,不小心打错了字,框架是选择忽略还是报错提醒呢,因为那个它不认识的标签,可能是别家的啊?所以,在这点上,React 的做法有优胜的地方。
还有,React 里面几乎所有的东西都是 Component,通过把 Component 进行高阶组合(HOC),确实可以产生威力无穷的变化。而且它的专有名词和概念,真的比 AngularJS 少太多(虽然其实东西都类似,只是 AngularJS 特意弄些名词出来)。如果能清晰理解 React 的单向数据流,和 HOC 的概念,上手应该说没 AngularJS 那么复杂。虽然老实说,HOC 可能和递归一样,对一些人来说,是非常不好理解的概念。
对于一个老程序员来说,对 React 最“看不顺眼的”,莫过于 JSX 这种把 “HTML” 标签写到 JavaScript 里的鬼玩意了。我们以前的教诲是,不能把逻辑代码和表现层混杂在一起。再加上,我个人一直觉得,一个结构清晰的表现层,可以清楚地展现页面概貌,对系统的设计和理解有很大的帮助。所以,一直以来,我是倾向于喜欢 AngularJS 式的页面模板(template)风格,然后在上面添加声明式的行为。但是,随着组件化理念的发展,页面已经无法避免被切分的命运。所以,只能思考哪种才是更合适,更清晰的模块化,低耦合,高内聚的方式。或许像 Polymer 那样的 Web Component 形式?知乎上一篇文章也讨论了 JSX有哪些缺陷?,大家不妨一看。
至于单向数据流,和双向数据绑定,老实说,我以前是喜欢双向绑定多一些的。某种程度上来说,框架从工具层面降低程序员的心智门槛,它自己计算和处理数据的变化就可以了。反正程序员可以假定最终数据是同步的,不管它是 dirty checking 还是什么方式。但是,面对复杂的页面行为和状态变更,把数据变为 Immutable,把变更控制在有限范围,尽量编写纯函数,确实可能更好。非纯函数和对外部全局的依赖,一不小心就会出问题。以前在玩 AngularJS 1 的时候,[自己就遇到坑了][]。
Flux
根据 React Component 绑定数据和接收事件的形式,Flux 是秉持单向数据流动里面的一种代码架构方式。
Flux 包含三大主要部分:Dispatcher, Store, 和 View(其实就是 React 的 Component)。它声称自己没有 MVC 里面的 Controller,但是有 Controller-View 和 Action Creator。真是受不了这些框架了,老是造一些名词,再标榜和以前不同。其实别管那么多,最重要的是搞清楚数据的流动情况,数据的流动情况,数据的流动情况。
下面我拿消息列表的例子来说明 Flux 里面的主要部分是怎么关联,数据在里面是怎么流动的。
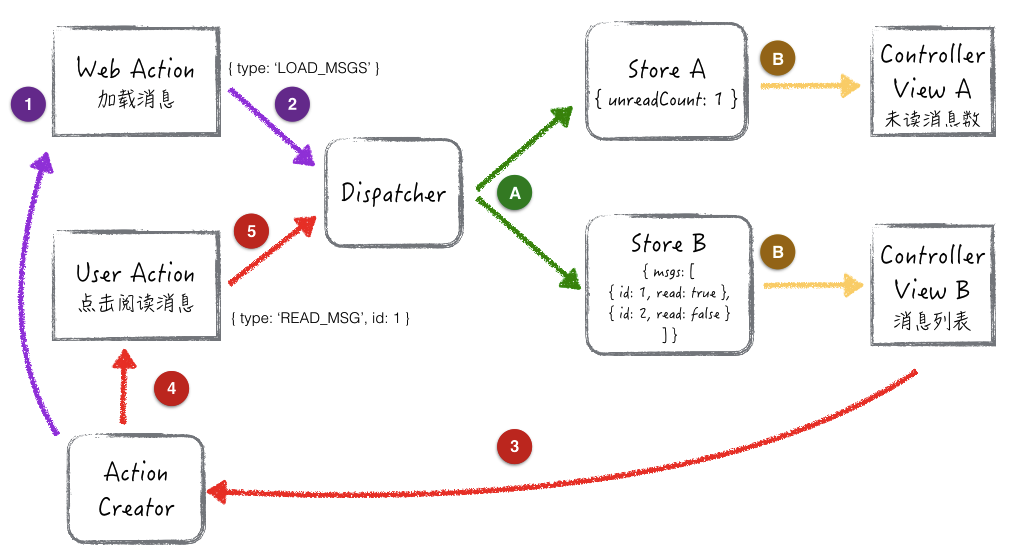
这里有两个场景:
页面打开,自动加载消息
这个场景的数据流动路线是:1 -> 2 -> A -> B
页面打开的时候,Action Creator 把 LOAD_MSGS 这个 Action 推给 Dispatcher。两个 Store 都会接收到这个 Action。Store B 把数据赋予 msgs,更改了内部 State,然后更新 View B。
Store A 呢?Store A 里面的 unreadCount 状态数据,是依赖 Store B 里面的 msgs 计算出来的。所以,Store A 里的处理逻辑其实会忽略接收到的 Action,通过 Dispatcher.waitFor 的方法,声明必须等待 Store B 的计算完成,然后 derive 自己需要的数据,再更新 View A。
用户点击阅读某一条消息
这个场景的数据流动路线是:3 -> 4 -> 5 -> A -> B
当用户点击某一条消息时,Action Creator 接收到 View B 的事件,构造了包含消息 id 的 READ_MSG Action,推给 Dispatcher。紧接着的操作类似上面的场景,不再累述。
结合场景来理解数据的流动,就能比较容易搞清楚 Flux 组成部分的定义了。
- Dispatcher 是全局的,只有一个。
- Action Creator 负责接收 View 的事件,产生 Action。当然也可以按需,自己产生 Action。
- Action 只是简单的操作指令,包含必要的数据,但是没有处理逻辑。
- Store 有多个,同时接收所有的 Action,按各自处理 Logic,改变数据内部 State。
View 和 Controller View 的不同在于,Controller View 负责接收 Store 广播出来的事件,然后把更新的数据扩散下去其它的 View。所以 Controller View 是接近于顶层的。
Redux
Redux 又是什么鬼呢?有人问 Redux 算不算是 Flux 架构的一种实现。Redux 作者说它既是,又不是。有兴趣的朋友自己看文档官网里,作者引的 Tweet 吧。神仙也会打架的,就是因为各自造不同的名词出来。
那在这个框架底下,数据的流动又是如何的呢?我们通过上面同样的场景来看一下:
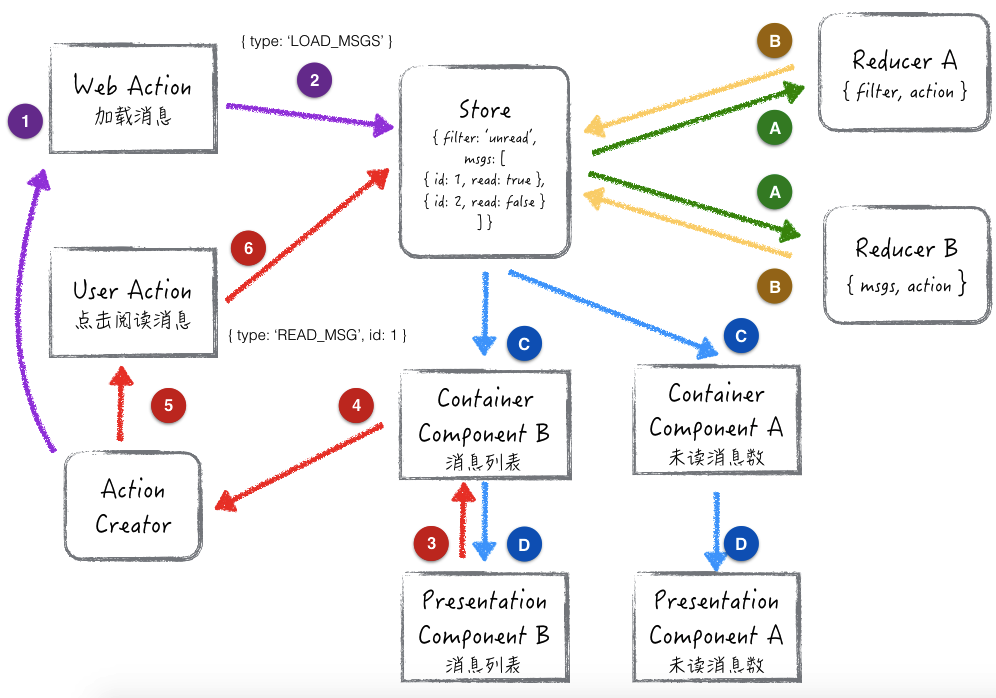
页面打开,自动加载消息
这个场景的数据流动路线是:1 -> 2 -> A -> B -> C -> D
页面打开的时候,Action Creator 把 LOAD_MSGS 这个 Action 作为参数调用 Store.dispatch 方法。然后和 Store 绑定的所有 Reducer 都会接收到 Action,和它们各自负责的部分 State 结构。Store 再把各个 Reducer 计算后的新 State 合并。Container Component 把 State 的数据转换成 Presentation Component 需要的 Property 和绑定事件。
用户点击阅读某一条消息
这个场景的数据流动路线是:3 -> 4 -> 5 -> 6 -> A -> B -> C -> D
当用户点击某一条消息时,Presentation Component B 接收到用户操作,通过 Container Component B 绑定在它之上的事件,通知 Action Creator 构造了包含消息 id 的 READ_MSG Action,调用 Store.dispatch 方法通知 Reducers。后面的数据流动和上面类似。
下面解释一下 Redux 和 Flux 的不同,以及里面各个部分的关键定义。
- 全局单一的 State(作者声称的 Single source of truth)。
- 没有 Dispatcher(实际上统一的 Store 承担了 Dispatcher 的功能)。
- Reducer 应该是 pure function 纯函数。而且它们同步更新各个部分的 state,最后汇总。
- State is Readonly。任何改动都不改变原有的数据,而是生成新的数据。
- Container Component 相当于 Flux 的 Controller View。Presentation Component 是普通的 View。
- Action 和 Action Creator 基本是一样的。
Redux 的关键不同之处是,它只有统一的 State。所以,从一开始就要尽量设计好 State 的结构。官网上还特别提到,数据应该要 normalized,就像 RDBMS 里面存储数据那样,尽量用 id 来指向数据,不冗余。
所以,在 Redux 这里,我并没有添加 unreadCount 这个属性给 Component A。它们应该直接从 msgs 里面的消息里推算出来。还有,如果出现前面说的 State 里面如果有数据相互影响的情况,我觉得可能需要在某个 Action 运算后再 dispatch 新 action 出来。因为 Reducers 的调用都是同步的,而且好像无法指定执行顺序。不过这部分我还不太确定,需要实践和再查找资料。