听听系统的多地部署改造
Updated:
很早就想过写这篇文章了,一直没动手。
直播系统卡壳
在一块听听刚上线不久,我们就迎来了一个 6W 人的直播。当天,直播开始时间前后 10 分钟那个区间,系统是真的卡的不行。 用户打不开页面,进不了直播间,老师发言也发不出去。
当时真的是心急火燎,但是又没有什么能做。真的只能慢慢等时间流逝,压力下来,进直播间的人都稳定了,系统也就平稳了。是什么导致那么狼狈呢?
时间和规划不足
整个系统国庆后开始开发,11月12日功能才基本完整上线并迎来第一个直播,这个大直播(12月13日)就来了。这期间还忙着需求开发,没足够时间做性能测试。
不必要的接口开销多。
用户有两个途径进入直播间,一个是直达直播间的微信通知的消息链接,另一个是「我的」菜单按钮。当时「我的」个人页面,前端一共调用 4 个接口:
- 获取用户资料
- 获取用户发起的直播
- 获取用户购买的直播
- 获取其它更多相关的直播
频繁查写库,没充分利用缓存
我们没很好利用缓存。而且,一开始是区分提问和非提问票的。在用户冲入直播间(或者刷新直播间页面)的时候,我们都必须获取用户提问发言次数,看是否已经超出限额。这些操作当时都是直接读写数据库,导致缓慢。
业务导致网络开销大
我们当时的直播间做的很实诚,每进退一个人,都在上面显示实时人数。这个人数变动的消息广播,对网络影响相当大。
不必要实时显示的数据
我们的直播间还有一个打赏榜,当时的打赏情况实在是火热,很多人频繁刷打赏榜,实时从数据库拉取数据。另一个加重服务压力的方面,用户每进出一次打赏榜就要出直播间和再返回一次,导致更频繁的进入直播间请求。
优化之路
经此一役,并听说罗永浩又要来直播(1月16号),量可能更大,我们就迅速准备调整了。
业务调整
业务功能,是有可能对性能影响很大的。当然,不是说有了性能问题,就只能调整业务。而是,如何恰当地在业务功能上做出可接受的妥协,使得性能优化更可行。
曹政公众号的文章也举了类似的例子,搜索引擎的翻页功能。百度最多 49 页,Google 更少,6 页就没了。其实搜索根本没必要支持很多页,因为真正的用户,翻三四页没找到要的信息就会调整关键字了,怎么可能翻上百页。
我们去除了提问票,就没有必要在进入直播间的时候写数据库了。当然,调整的主要原因不是因为性能,而是产品和业务的考虑。具体原因有机会再分享。假设还是有提问需求,那么,检查提问次数的逻辑,可以调整为前端缓存检查,没太大必要那么严格的在进入直播间的时候,通过后端检查。
接口控制
如前面所说,根据页面功能的规划,我们可以确定不同区域的重要程度和降级方案。然后,通过接口动态屏蔽的功能,前端可以在特殊时候减少网络请求。
前面提到的4个接口,接口1 其实前端可以使用客户端缓存;接口2 只有少数是主讲人的用户才需要;接口4 是非常耗费资源,计算复杂的接口。但是获取其它更多相关的直播,在大直播来临的时候,其实可以完全屏蔽,因为这个时候多数用户关注点不在这里。
减少网络开销
面临大规模访问时候,网络数据的大小和频率会非常影响系统稳定性。
如前面所说,socket 服务器的实时人数的消息广播,真的很占网络资源。后来业务上也觉得这个信息不太需要,也就直接去掉了。去掉了后,Socket 可支撑的同时在线人数马上上去了。
另一个是进入直播间后 http 服务器返回的数据,也作出精简。只有第一眼用户需要看到的数据,才拿出来。一些其它支持用户其它操作的数据,可以等用户需要的时候,再让前端发请求获取。
增加缓存,非实时数据异步处理
打赏榜的数据,在大直播刚开始时,其实并没有太强烈的实时聚合打赏数据排名的要求。所以,后期我们通过异步任务后台聚合,放缓存,前端直接从缓存拿数据。
除了后端优化,前端方面,我们还可以动态禁止查看打赏榜。进入打赏榜的时候,不再需要离开直播间,而是弹出一个新的层,减少直播间进出的情况,带来不必要的网络请求。
多地部署,读写分离
虽然,不是说性能不行,就马上要横向扩展和实现多地架构,但当时青云的北京区服务器,华南,华东一些偏远地区平时访问也有点慢,网络有时还会抽风。多地部署可以让全国不同省市的人,访问最近的服务。而且,罗永浩直播的人数真是不好预估,所以,我们还是担心只有一个区的服务器和网络可能撑不住。
下面是一开始的服务架构:
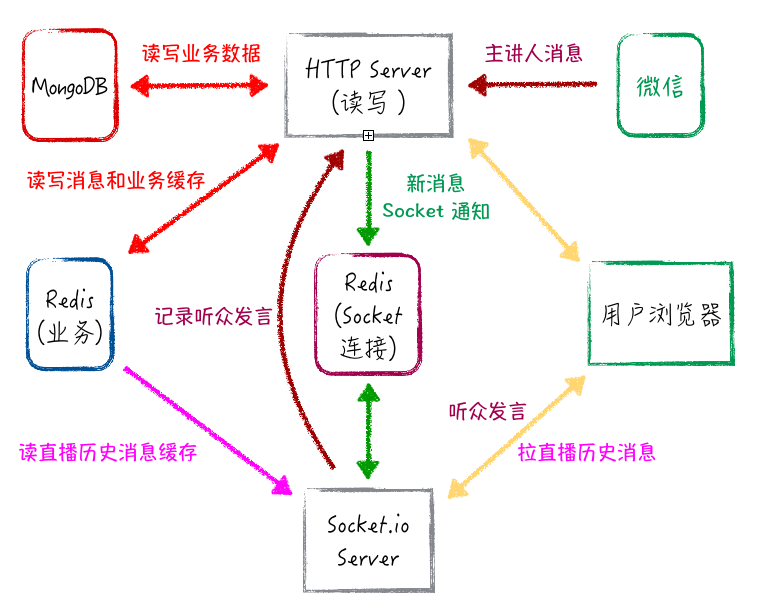
因为我们实现多地部署要达成的最基本的目标是:增加缓存,每个分区独立运作,承担各自的压力,互不影响,也就是按区域横向扩展。所以,每个只读的分区,应该要有独立的 Redis,HTTP Server 和 Socket Server。
增加缓存,多地部署后要面对的最直接的问题是:
- 什么数据适合放在缓存?
直播详情,用户购买记录等一些高频查询数据,我们都放在缓存里。这个问题在以前的文章「业务与缓存」有更详细的介绍,这里就不重复了。
- 有数据改动的时候,如何失效各分区的缓存呢?
目前,我们依赖的是 Redis 的 Pub/Sub 机制。主区有新的数据改动的时候,publish 消息到特定的 channel。各个独立分区的 Subscriber 监听到消息通知,就失效掉特定的缓存。
最后,新的服务架构如下:
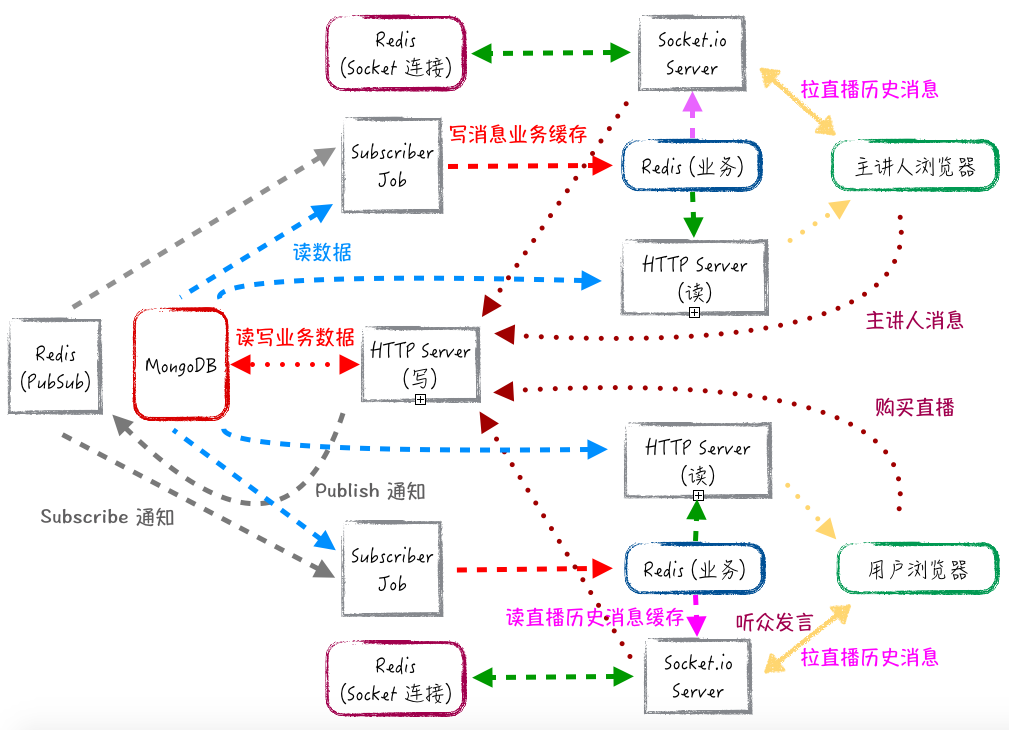
MongoDB,HTTP Server(写)这些负责写的部分,和 Redis (PubSub) 是公共的,其它部分其实是不同分区独立拥有的相同的组件。我在上面标注主讲人,下面标注普通用户,只是为了容易看一些,它们实际是完全一样的。这样的架构,有需要的时候,复制不同的读分区出来服务不同地区的用户就比较容易了。
还能做什么?
现在这个架构,服务器之间的通信还是挺复杂的,网络占用应该还有更多优化空间。当时罗永浩直播刚开始的时候,某些用户还出现了“已经在其它终端登录”的警告而被踢出直播间。可是这个问题一直没时间细查。
这个架构,其实还不是真正意义的异地多活,和分布式系统,因为数据库和写服务器还是单一的。目前我们做这个的话,成本还是太高。不过,或许以后真的要再一次重构,也应该是服务的细分,SOA 更靠谱一些。